🟡 Diverse Prompts
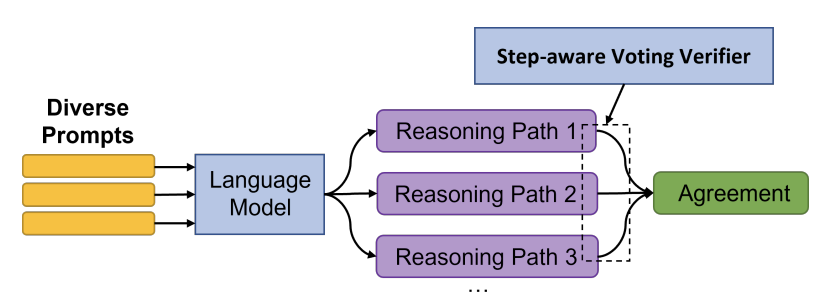
DiVeRSe1 ("Diverse Verifier on Reasoning Steps") is a method that improves the reliability of answers in a threefold manner. It does this by 1) using multiple prompts to generate diverse completions, 2) using a verifier to distinguish good answers from bad answers, and 3) using a verifier to check the correctness of reasoning steps.
Diverse Prompts
DiVeRSe uses 5 different prompts a given input. To construct each prompt, they randomly sample a few exemplars from the training set. Here is an example of one such few-shot prompt (k=2), with exemplars taken from the GSM8K benchmark2. In practice, DiVeRSe uses 5 exemplars in prompts for this benchmark.
Q: Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?
A: Natalia sold 48/2 = 24 clips in May.
Natalia sold 48+24 = 72 clips altogether in April and May.
#### 72
Q: Weng earns $12 an hour for babysitting. Yesterday, she just did 50 minutes of babysitting. How much did she earn?
A: Weng earns 12/60 = $0.2 per minute.
Working 50 minutes, she earned 0.2 x 50 = $10.
#### 10
Q: Betty is saving money for a new wallet which costs $100. Betty has only half of the money she needs. Her parents decided to give her $15 for that purpose, and her grandparents twice as much as her parents. How much more money does Betty need to buy the wallet?
A:
After generating 5 different prompts like above, DiVeRSe samples 20 reasoning paths for each (temperature = 0.5). Here are a few example completions of the above prompt. Note that the answers are not always correct.
Betty has 0.5*100 = $50.Then she gets 15 more = $65.Then she gets 2*15 = $90.She needs 100-90 = $10 more.#### 10A: Betty has 0.5*100 = $500.Then she gets 15 more = $650.Then she gets 2*15 = $900.She needs 100-90 = $1000 more.#### 1000At this point, DiVeRSe has generated 100 different completions.
Voting Verifier
Now, we could just take the majority answer, like Self-Consistency3 does.
However, DiVeRSe proposes a much more complicated method, which they call a voting verifier.
At test time, using the voting verifier is a two step process. First, the verifier (a neural network) assigns a 0-1 score to each completion based on how likely it is to be correct. Then, the 'voting' component sums all of the scores over different answers and yields the final answer.
Example
Here is a small example. Say we have the following completions for the prompt What is two plus two?:
4two + 2 = 5I think 2+2 = 6two plus two = 4It is 5The verifier will read each completion and assign a score to it. For example, it might assign the scores: 0.9, 0.1, 0.2, 0.8, 0.3 respectively. Then, the voting component will sum the scores for each answer.
score(4) = 0.9 + 0.8 = 1.7
score(5) = 0.1 + 0.3 = 0.4
score(6) = 0.2
The final answer is 4, since it has the highest score.
But how is the verifier trained?
The verifier is trained with a slightly complex loss function, which I will not cover here. Read section 3.3 of the paper for more details1.
Takeaways
The main take away here is to use multiple prompts to generate diverse completions. In practice, majority voting will likely work well compared to the voting verifier.
- Li, Y., Lin, Z., Zhang, S., Fu, Q., Chen, B., Lou, J.-G., & Chen, W. (2022). On the Advance of Making Language Models Better Reasoners. ↩
- Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., Hesse, C., & Schulman, J. (2021). Training Verifiers to Solve Math Word Problems. ↩
- Mitchell, E., Noh, J. J., Li, S., Armstrong, W. S., Agarwal, A., Liu, P., Finn, C., & Manning, C. D. (2022). Enhancing Self-Consistency and Performance of Pre-Trained Language Models through Natural Language Inference. ↩