🔴 Soft Prompts
Prompt tuning1, an alternative to model fine tuning2, freezes the model weights, and updates the parameters of a prompt. The resultant prompt is a 'soft prompt'.
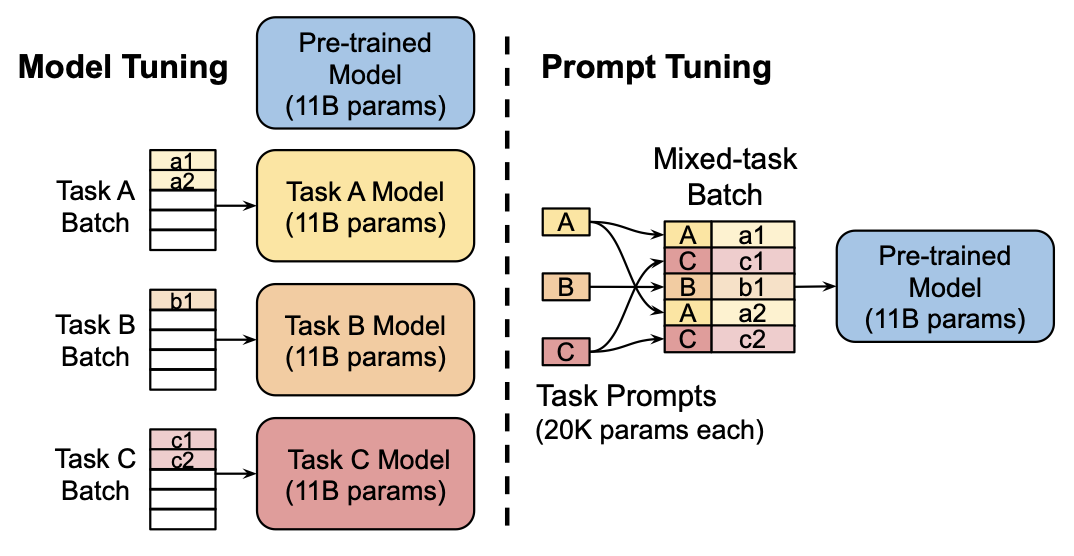
The above image contrasts model tuning with prompt tuning. In model tuning, you finetune the same model on different tasks. This gives you a few different models, with which you can't necessarily batch inputs easily.
On the other hand, prompt tuning lets you use the same model for all tasks. You just need to append the proper prompts at inference time, which makes batching across different tasks easier. This is pretty much the same advantage that regular prompting has. Additionally, soft prompts trained for a single model across multiple tasks will often be of the same token length.
How it works
To understand the basic logic behind soft prompting, let's think about how model inference works
on a given prompt: What's 2+2?.
1) It might be tokenized as What, 's, 2, +, 2, ?.
2) Then, each token will be converted to a vector of values.
3) This vectors of values can be considered as model parameters. The model can be further trained, only adjusting the weights of these prompts.
Note that as soon as we start updating these weights, the vectors of the tokens no longer correspond to actual embeddings from the vocabulary.
Results
Prompt tuning performs better with larger models. Larger models also require less soft prompt tokens. Regardless, more than 20 tokens does not yield significant performance gains.
- Lester, B., Al-Rfou, R., & Constant, N. (2021). The Power of Scale for Parameter-Efficient Prompt Tuning. ↩
- Khashabi, D., Lyu, S., Min, S., Qin, L., Richardson, K., Welleck, S., Hajishirzi, H., Khot, T., Sabharwal, A., Singh, S., & Choi, Y. (2021). Prompt Waywardness: The Curious Case of Discretized Interpretation of Continuous Prompts. ↩