🟡 LLMs that Reason and Act
ReAct1(reason, act) is a paradigm for enabling language models to solve complex tasks using natural language reasoning. ReAct is designed for tasks in which the LLM is allowed to perform certain actions. For example, as in a MRKL system, a LLM may be able to interact with external APIs to retrieve information. When asked a question, the LLM could choose to perform an action to retrieve information, and then answer the question based on the retrieved information.
ReAct Systems can be thought of as MRKL systems, with the added ability to reason about the actions they can perform.
Examine the following image. The question in the top box is sourced from HotPotQA2, a question answering dataset that requires complex reasoning. ReAct is able to answer the question by first reasoning about the question (Thought 1), and then performing an action (Act 1) to send a query to Google. It then receives an observation (Obs 1), and continues with this thought, action, observation loop until it reaches a conclusion (Act 3).
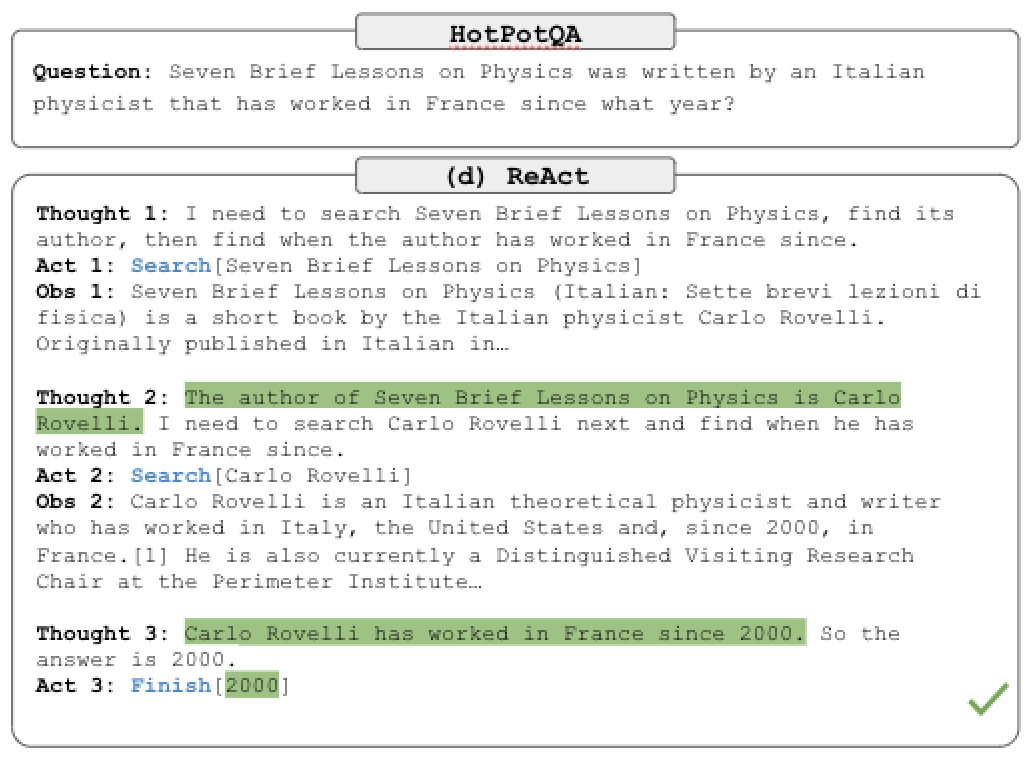
Readers with knowledge of reinforcement learning may recognize this process as similar to the classic RL loop of state, action, reward, state,... ReAct provides some formalization for this in their paper.
Results
Google used the PaLM3 LLM in experiments with ReAct. Comparisons to standard prompting (question only), CoT, and other configurations show that ReAct's performance is promising for complex reasoning tasks. Google also performs studies on the fever dataset4, which covers fact extraction and verification.

- Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., & Cao, Y. (2022). ReAct: Synergizing Reasoning and Acting in Language Models. ↩
- Yang, Z., Qi, P., Zhang, S., Bengio, Y., Cohen, W. W., Salakhutdinov, R., & Manning, C. D. (2018). HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering. ↩
- Chowdhery, A., Narang, S., Devlin, J., Bosma, M., Mishra, G., Roberts, A., Barham, P., Chung, H. W., Sutton, C., Gehrmann, S., Schuh, P., Shi, K., Tsvyashchenko, S., Maynez, J., Rao, A., Barnes, P., Tay, Y., Shazeer, N., Prabhakaran, V., … Fiedel, N. (2022). PaLM: Scaling Language Modeling with Pathways. ↩
- Thorne, J., Vlachos, A., Christodoulopoulos, C., & Mittal, A. (2018). FEVER: a large-scale dataset for Fact Extraction and VERification. ↩