🟡 具有推理和行动能力的LLMs
ReAct1(reason, act)是一种使用自然语言推理解决复杂任务的语言模型范例。ReAct旨在用于允许LLM执行某些操作的任务。例如,在MRKL系统中,LLM可以与外部API交互以检索信息。当提出问题时,LLM可以选择执行操作以检索信息,然后根据检索到的信息回答问题。
ReAct系统可以被视为具有推理和行动能力的MRKL系统,。
请查看以下图像。顶部框中的问题来自HotPotQA2,这是一个需要复杂推理的问答数据集。 ReAct能够首先通过推理问题(Thought 1),然后执行一个动作(Act 1)来向Google发送查询来回答问题。然后它收到了一个观察(Obs 1),并继续进行这个思想,行动,观察循环,直到达到结论(Act 3)。
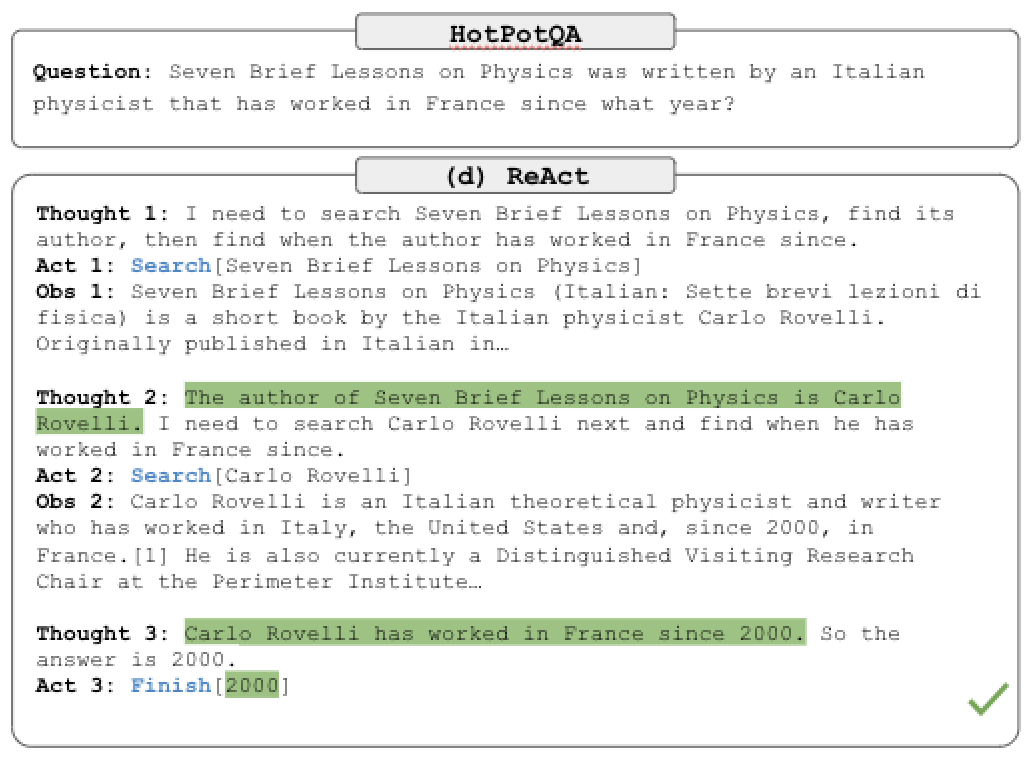
ReAct System (Yao et al.)
具有强化学习知识的读者可能会认为,这个过程类似于经典的RL循环:状态,行动,奖励,状态,...。ReAct在其论文中对此进行了一些规范化。
结论
谷歌在ReAct的实验中使用了PaLM3 LLM。与标准提示(仅问题)、CoT和其他配置进行比较表明,ReAct在复杂推理任务方面的表现是有希望的。谷歌还对涵盖事实提取和验证的Fever数据集4进行了研究。

ReAct Results (Yao et al.)
- Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., & Cao, Y. (2022). ReAct: Synergizing Reasoning and Acting in Language Models. ↩
- Yang, Z., Qi, P., Zhang, S., Bengio, Y., Cohen, W. W., Salakhutdinov, R., & Manning, C. D. (2018). HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering. ↩
- Chowdhery, A., Narang, S., Devlin, J., Bosma, M., Mishra, G., Roberts, A., Barham, P., Chung, H. W., Sutton, C., Gehrmann, S., Schuh, P., Shi, K., Tsvyashchenko, S., Maynez, J., Rao, A., Barnes, P., Tay, Y., Shazeer, N., Prabhakaran, V., … Fiedel, N. (2022). PaLM: Scaling Language Modeling with Pathways. ↩
- Thorne, J., Vlachos, A., Christodoulopoulos, C., & Mittal, A. (2018). FEVER: a large-scale dataset for Fact Extraction and VERification. ↩