🟢 用GPT-3构建ChatGPT

介绍
ChatGPT在过去一个月内爆炸性增长,仅一周内就获得了一百万用户。令人惊讶的是,其基础模型GPT-3在2020年首次亮相,并在一年前公开了对外访问权限!
ChatGPT是一种新的语言模型,由OpenAI进行了优化,从GPT-3进行了微调,使其能够用于对话1。它具有用户友好的聊天界面,您可以通过它输入内容并获得AI助手的响应。请在chat.openai.com上查看。
尽管早期版本的GPT-3没有当前的GPT-3.5系列那么先进,但它们仍然令人印象深刻。这些模型通过API和Playground Web UI界面提供,让您调整某些配置参数并测试提示。GPT-3取得了显着的关注,但它并没有达到ChatGPT的病毒式传播。
与GPT-3相比,ChatGPT之所以如此成功,是因为它作为一个简单的AI助手对于普通人来说非常易于使用,无论他们对数据科学、语言模型或AI的知识有多少。
在本文中,我将概述如何使用像GPT-3这样的大型语言模型来实现ChatGPT等聊天机器人。
动机
本文部分原因是由Riley Goodside的一条推文引发的,他指出了ChatGPT是如何实现的。
How to make your own knock-off ChatGPT using GPT‑3 (text‑davinci‑003) — where you can customize the rules to your needs, and access the resulting chatbot over an API. pic.twitter.com/9jHrs91VHW
— Riley Goodside (@goodside) December 26, 2022
与GPT-3.5系列中的其他模型一样,ChatGPT是使用RLHF进行训练的,但它的大部分效果来自于使用了好的提示。
提示

Skippy chatbot完整的提示(prompt)
ChatGPT 是一个语言模型和用户界面。用户输入到界面的提示实际上被插入到包含用户和 ChatGPT 之间整个对话的较大提示中。这使得基础语言模型能够理解对话的上下文并作出适当的回应。
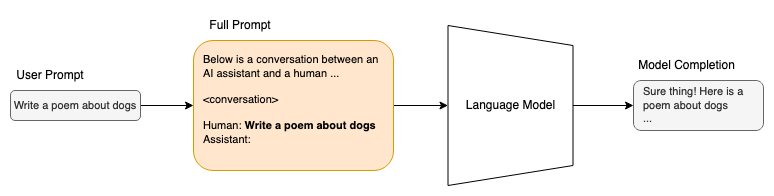
在发送到模型之前插入用户提示的示例
语言模型通过在预训练过程中学习的概率来完成提示,从而确定接下来的词汇2。
GPT-3 能够从简单的指令或几个示例中“学习”。后者被称为少样本或上下文学习3。在上面的聊天机器人提示中,我创建了一个虚构的聊天机器人命名为 Skippy,并指示它向用户提供回应。GPT-3 明白了来回交流的格式 USER: {user input} 和 SKIPPY: {skippy response}。GPT-3 理解 Skippy 是一个聊天机器人,之前的交流是一段对话,因此当我们提供下一个用户输入时,“Skippy”将作出回应。
记忆
Skippy和用户之间的过去交流会附加到下一个提示中。每次我们提供更多用户输入并获得更多聊天机器人输出时,提示都会扩展以纳入这个新交流。这就是Skippy和ChatGPT这样的聊天机器人如何记住以前的输入。但是,GPT-3聊天机器人可以记住的内容是有限的。
提示在进行多次交流后可能会变得很庞大,特别是如果我们使用聊天机器人来生成像博客文章这样的长篇回复。发送到GPT-3的提示将转换为标记(tokens),这些标记(tokens)是单个单词或其中的一部分。对于包括ChatGPT在内的GPT-3模型,组合提示和生成响应的标记限制为4097个(约3000个单词)。
几个例子
保存先前对话的提示有许多不同的用途。 ChatGPT旨在成为一个多功能的通用助手,在个人使用的经验中,它很少会要求一些后续跟进的问题。
询问你近况的心理治疗师聊天机器人
拥有一个主动询问问题并从用户那里获得反馈的聊天机器人可能会很有帮助。下面是一个关于治疗师聊天机器人的示例,它将询问问题和后续问题,以帮助用户思考他们的一天。

治疗师聊天机器人
使用旧的日记与年轻的自己交谈
Michelle Huang使用GPT-3与她的年轻自己聊天。提示(Prompt)使用了一些上下文,例如旧的日记,配对聊天机器人样式的问答格式。 GPT-3能够根据这些条目模仿一种人格。i trained an ai chatbot on my childhood journal entries - so that i could engage in real-time dialogue with my "inner child"
— michelle huang (@michellehuang42) November 27, 2022
some reflections below:
提示的内容:
以下是一段现在Michelle(年龄[已隐去])与14岁的年轻自己之间的对话,年轻的Michelle曾写下以下的日记:
[日记内容在此处]
现在的Michelle: [在此处输入你的问题]
作者指出日记条目可能会达到token的限制。在这种情况下,你可以挑选几个条目或者尝试概括几个条目。
实现
我将介绍如何在Python中编写一个简单的GPT-3驱动聊天机器人。使用OpenAI API将GPT-3包含在您正在构建的应用程序中非常容易。您需要在OpenAI上创建一个帐户并获取API密钥。请查看他们的文档这里。
我们需要完成以下步骤:
- 格式化用户输入以便于GPT-3的聊天机器人
- 从GPT-3获取聊天机器人响应作为完成
- 使用用户的输入和聊天机器人的响应更新提示
- 循环
这是我将要使用的提示。我们可以使用python将<conversation history>和<user input>替换为它们的实际值。
chatbot_prompt = """
作为一个高级聊天机器人,你的主要目标是尽可能地协助用户。这可能涉及回答问题、提供有用的信息,或根据用户输入完成任务。为了有效地协助用户,重要的是在你的回答中详细和全面。使用例子和证据支持你的观点,并为你的建议或解决方案提供理由。
<conversation history>
User: <user input>
Chatbot:"""
我跟踪下一个用户输入和上一个对话。每个循环之间,聊天机器人和用户之间的新输入/输出都会附加到对话历史中。
import openai
openai.api_key = "YOUR API KEY HERE"
model_engine = "text-davinci-003"
chatbot_prompt = """
作为一个高级聊天机器人,你的主要目标是尽可能地协助用户。这可能涉及回答问题、提供有用的信息,或根据用户输入完成任务。为了有效地协助用户,重要的是在你的回答中详细和全面。使用例子和证据支持你的观点,并为你的建议或解决方案提供理由。
<conversation history>
User: <user input>
Chatbot:"""
def get_response(conversation_history, user_input):
prompt = chatbot_prompt.replace(
"<conversation_history>", conversation_history).replace("<user input>", user_input)
# Get the response from GPT-3
response = openai.Completion.create(
engine=model_engine, prompt=prompt, max_tokens=2048, n=1, stop=None, temperature=0.5)
# Extract the response from the response object
response_text = response["choices"][0]["text"]
chatbot_response = response_text.strip()
return chatbot_response
def main():
conversation_history = ""
while True:
user_input = input("> ")
if user_input == "exit":
break
chatbot_response = get_response(conversation_history, user_input)
print(f"Chatbot: {chatbot_response}")
conversation_history += f"User: {user_input}\nChatbot: {chatbot_response}\n"
main()
现在只需要构建一个漂亮的前端,让用户可以与之交互!
Written by jayo78.
- OpenAI. (2022). ChatGPT: Optimizing Language Models for Dialogue. https://openai.com/blog/chatgpt/. https://openai.com/blog/chatgpt/ ↩
- Jurafsky, D., & Martin, J. H. (2009). Speech and Language Processing: An Introduction to Natural Language Processing, Computational Linguistics and Speech Recognition. Prentice Hall. ↩
- Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D. M., Wu, J., Winter, C., … Amodei, D. (2020). Language Models are Few-Shot Learners. ↩