🟡 提示多样性
DiVeRSe1 ("Diverse Verifier on Reasoning Steps") 是一张通过三重方式提高答案可靠性的方法。它通过使用多个提示生成多样化的补全结果(completions),使用验证器区分好的答案和坏的答案,并使用验证器检查推理步骤的正确性。
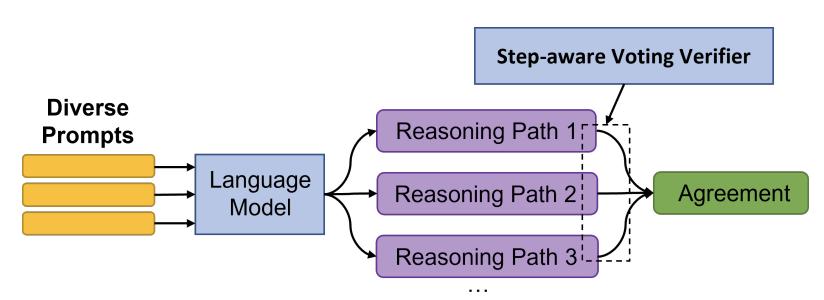
提示多样性
DiVeRSe使用五个不同的提示来对给定的输入进行编码。为了构造每个提示,他们随机从训练集中抽取几个样例。以下是一个样本(k = 2)的少量数据提示,其中样例取自GSM8K 基准测试2。在此基准测试中,DiVeRSe使用5个样例来构建提示。
Q:Natalia在4月份向她的48个朋友出售了夹子,然后在5月份卖出了一半。 Natalia在四月和五月共卖了多少个夹子?
A:Natalia在五月份卖出了48/2 = 24个夹子。
Natalia在四月和五月共卖出了48 + 24 = 72个夹子。
#### 72
Q:Weng为照看孩子每小时赚取12美元。昨天,她只照看了50分钟。她赚了多少钱?
A:翁每分钟赚12/60 = 0.2美元。
工作50分钟,她赚了0.2 x 50 = 10美元。
#### 10
Q:贝蒂正在为一只价值100美元的新钱包存钱。贝蒂只有一半的钱。她的父母决定给她15美元,并且她的祖父母比她的父母多两倍。贝蒂还需要多少钱才能买钱包?
A:
在生成类似上面的5个不同提示之后,DiVeRSe为每个提示(temperature = 0.5)采样20条推理路径。以下是上述提示的几个样本的补全结果。请注意,答案并不总是正确的。
Betty有0.5*100 = $50。然后她又得到了15美元 = $65。然后她又得到了2*15美元 = $90。她还需要100-90 = $10。#### 10A: Betty有0.5*100 = $500。然后她又得到了15美元 = $650。然后她又得到了2*15美元 = $900。她还需要100-90 = $1000。#### 1000此时,DiVeRSe已经生成了100个不同的完成。
投票验证器
现在,我们可以像自洽性3一样,直接采用多数答案。
但是,DiVeRSe提出了一种更复杂的方法,称为投票验证器。
在测试时,使用投票验证器是一个两步过程。首先,验证器(一个神经网络)根据其可能正确的概率为每个补全结果分配0-1分数。然后,“投票”组件对不同答案的所有分数进行求和,并产生最终答案。
样本
这里是一个小例子。假设对于二加二等于几?这个提示的补全结果是这样的:
4二 + 2 = 5我想 2+2 = 6二加二 = 4答案是5验证器将读取每个补全结果并为其分配分数。例如,它可能分配以下分数:0.9,0.1,0.2,0.8,0.3。然后,“投票”组件将对每个答案的分数进行求和。
score(4) = 0.9 + 0.8 = 1.7
score(5) = 0.1 + 0.3 = 0.4
score(6) = 0.2
最终答案是4,因为它具有最高的分数。
但验证器是如何训练的?
验证器使用稍微复杂的损失函数进行训练,在这里不进行详细介绍。请阅读论文3.3节以获取更多细节1。
总结
这里主要是使用多个提示来生成多样化的补全结果。在实践中,与投票验证相比,多数投票可能效果更好。
- Li, Y., Lin, Z., Zhang, S., Fu, Q., Chen, B., Lou, J.-G., & Chen, W. (2022). On the Advance of Making Language Models Better Reasoners. ↩
- Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., Hesse, C., & Schulman, J. (2021). Training Verifiers to Solve Math Word Problems. ↩
- Mitchell, E., Noh, J. J., Li, S., Armstrong, W. S., Agarwal, A., Liu, P., Finn, C., & Manning, C. D. (2022). Enhancing Self-Consistency and Performance of Pre-Trained Language Models through Natural Language Inference. ↩